
SLI/SLOをストリームアラインドチームに導入した話
この記事は Ubie Engineers & Designers Advent Calendar 2022 23日目の記事です。
今、ぼくは Ubie Discoveryでプロダクト開発エンジニアをしています。(入社エントリ)
今回はチームトポロジー導入により誕生したストリームアラインドチームにおいて、SLI/SLOをどう導入していったのかという点に注目してお話していきます。
チームトポロジーを導入したお話は、同僚の八木さんが記事にしているのでよかったら読んでみてください!
SLI/SLOの前に
チームトポロジーからSLI/SLOの話にいきなり行くのはちょっと乱暴なので、もう少しここについてお話します。
ストリームアラインドチームとは、ざっくりいうとユーザーに価値を届け続けるチームです。価値を届け続けるために必要なことすべてに対して責任を持ちます。
機能開発をするだけではなく、ディスカバリ、カスタマーサクセス、ユーザーサポートやシステム運用も含まれています。
そんな中、特に運用面においてですが、やりたいこと、やらなきゃいけないことは無数にある中で、機能開発を含めたその他の業務と比較して優先順位をつけることが難しい問題が出て来ました。
システム運用の観点では、緊急ではないけど重要な課題が多く、中長期的な視点も必要になってきます。それと比べると新価値開発は短期的で今すぐやることが求められることが多いですよね。
何もしていないと、運用はすべて後回しにして新価値開発にすべてのリソースを使うという力学が働きやすくなります。
このバランスをいかに取るかという点で、ぼくたちはSLI/SLOを取り入れることにしました。
DevOpsという考え方を具体的なHowに落とし込んだのがSREであり、そのSREの一番基本となる手段がSLI/SLOの運用になります。
SLOを策定し、エラーバジェットの消費をモニタリングすることで、システム的な課題に取り組むのか、新価値のアクセルを踏むかのひとつの判断基準をつくることができます。
もちろん、これだけでは判断できない課題もありますが、ひとつの重要な指標としてSLOを使っていくことにしました。
また、SLI/SLOを決定するにあたっては、SREチームにイネイブリングチームとして協力してもらいました。
ユーザーがサービスをどう使っているのかを洗い出す
SLIは、価値をユーザーに届け続けられていることを確認するために計測する指標です。
SLIを決めるためには、サービスをユーザーがどのように利用し、どこで価値を得ているのかを確認する必要があります。
ぼくはUbieに入社して日も浅かったので、まずはここをPOや医師、同僚のエンジニアなど、サービスを熟知しているメンバーに聞いていくことから始めました。

Ubieがユーザーに提供している価値は様々です。
その中から、自ストリームアラインドチームが担当しているものを選定し、ビジネスへの影響度が大きい順に並べました。
SLIを決定する
上記で洗い出した価値のうち、どれを見ていくことで自ストリームアラインドチームの活動を決定できるかを考えました。
もちろんすべてを見られればいいのですが、SLIの数が膨大になっても混乱するばかりです。
今回はもっともビジネスへの影響度が大きいひとつの機能をターゲットとすることにしました。
対象を決めたら、ユーザーへ提供する価値が毀損しているかどうかを何で測るかを考える必要があります。これがSLIになります。
今回のケースでは、その機能がエラーになることなくユーザーが使えているか、また想定する時間内で提供できているかを見るのが一番よさそうです。
そのため、対象の機能の可用性とレイテンシをSLIとしました。
次にSLIをどこで計測するかですが、システムの内部的な値よりも、システムの境界となる部分でできるだけユーザーに近い場所で測れるものが望ましいです。
サービスを提供するプロダクトはReactで実装されたSPAであるため、当初はクライアントサイドでのレンダリングまわりを計測できないか考えました。
しかし今回の機能に関しては、クライアントサイドでのレンダリングよりも機能提供するために必要なAPIコールを計測したほうがいいという結論になりました。
ユーザーに近い位置で計測するため、サーバーサイドではなくクライアントサイドでAPIコールのレイテンシとステータスコードを計測することにします。
可用性に関しては、全アクセスのうちステータスコードが500系以外のものの割合を使います。
SLOを決定する
SLOの目標値と計測期間を次に決めます。
ここは自ストリームアラインドチームだけでなく、サービス全体を見ているグループのBizDevなどにも参加してもらって話し合いました。
いろいろ議論はあったのですが、ストリームアラインドチームとしてSLOを運用するのは初めてということもあり、目標値としては低めに設定しました。ここは運用を続けながら適正な値に近づけていきたいと考えています。
目標値にはもちろんセットで計測期間が必要です。今回は1ヶ月としました。
SLIのモニタリングとエラーバジェットの見える化
SLIとしては特定の機能のAPIコールだけ計測できればいいのですが、今後のことも考えてクライアントサイドでのAPIコールはすべて計測することにしました。
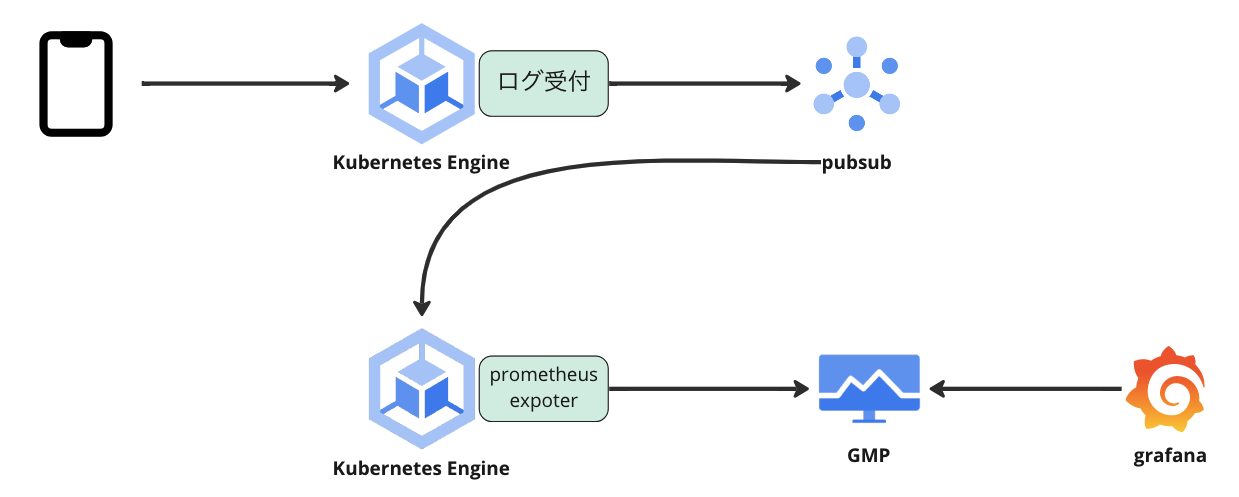
クライアントサイドで計測したAPIコールのレイテンシとステータスコードは、ログ集約を行っているサービスへ送られます。
ログ集約サービスはその情報をCloudPubsubへ流しているので、それをSubscribeしているサービス上でPrometheus Exporterを稼働させてています。
Prometheus Exporterの実装にはGoを使っています(UbieはGoとNode.jsの会社になります)。全APIのレイテンシを記録しているとカーディナリティが高くなりデータが膨大になってしまうため、exporterの処理でターゲットとなるAPIとそれ以外の2種類のメトリクスを出力するようにしています。生のデータ自体はpubsub経由でBigQueryにも保存しているため、後から詳細なデータを解析することも可能です。
exporterが稼働しているサービス上ではPodMonitoringリソースも定義しているので、Prometheus ExporterのメトリクスはGoogle Cloud Managed Service for Prometheus(GMP)が収集してくれます。
GMPにはSLI/SLOをモニタリングしたりエラーバジェットを管理してくれる機能もあるので、それらを簡単にgrafanaでグラフ化することができます。
まとめ
今回は、チームトポロジーを導入した組織のひとつのストリームアラインドチームで、新価値開発と運用のバランスを取るためにSLI/SLOを採用した話を簡単にまとめてみました。
SLI/SLOを導入するときにはいろいろと悩むポイントがあると思います。参考にしていただけたら幸いです。